

Rate Limits
Rate limits are restrictions that we impose on the number of times and tokens a user can access our API services within a specified period of time.
| Models | Basic TPM | Basic RPM |
|---|---|---|
voyage-4-large <br / >voyage-3-largevoyage-context-3voyage-code-3voyage 1&2 Series embedding models | 3M | 2000 |
voyage-4 <br / >voyage-3.5 | 8M | 2000 |
voyage-4-lite <br / >voyage-3.5-lite | 16M | 2000 |
voyage-multimodal-3.5, voyage-multimodal-3 | 2M | 2000 |
rerank-2.5-lite, rerank-2-lite, rerank-lite-1 | 4M | 2000 |
rerank-2.5, rerank-2, rerank-1 | 2M | 2000 |
For example, the voyage-3.5 API rate limits are set at 2000 RPM (requests per minute) and 8M TPM (tokens per minute), which means that a user or client is allowed to make up to 2000 API requests and process at most 8M tokens within one minute. Please refer to tokenization for the calculation of the number of tokens. Adhering to this limit ensures a balanced and efficient utilization of the API's resources, preventing excessive traffic that could impact the overall performance and accessibility of the service.
Usage tiers
You can view your organization’s rate limits in the organization Rate Limits section of the Voyage dashboard. As your usage and spending of the Voyage API increase, we automatically graduate you to the next usage tier, raising rate limits across all models. The table below summarizes the qualification criteria for each usage tier.
| Usage Tier | Qualification | Rate Limits |
|---|---|---|
| 1 | Payment method added. | See table above. |
| 2 | ≥ $100 paid | 2x Tier 1 |
| 3 | ≥ $1000 paid | 3x Tier 1 |
For example, at tier 2 and 3, the API rate limits for voyage-3.5 would increase to 16M TPM / 4000 RPM and 24M TPM / 6000 RPM, respectively. If you are at Tier 3, and need a higher rate limit, please request a rate limit increase.
Note: Usage tier qualification is based on billed usage, excluding free tokens for current models. Billing occurs monthly, and you can view your billing history in the Voyage dashboard. Purchasing usage credits count towards billed usage–see our FAQ for details. Once you qualify for a tier, you will never be downgraded to a lower tier.
Project rate limits
The rate limits above apply to your entire organization. Rate limits can also be set at the project level by the organization Admin. Project-level rate limits for each model can be any value less than or equal to the organization’s corresponding rate limit. For example, at usage tier 1, the voyage-3.5 API rate limit for a project can be set to 2000 RPM (requests per minute) and 8M TPM (tokens per minute), or lower.
Manage project rate limits
To manage project rate limits, select the desired project and navigate to the project Rate Limits section. Click the Select Models button in the upper-right corner.

To edit a model’s rate limit, click the pencil (Edit) icon in the model’s row. For example, in the screenshot below, we’ll be editing the voyage-3 model.
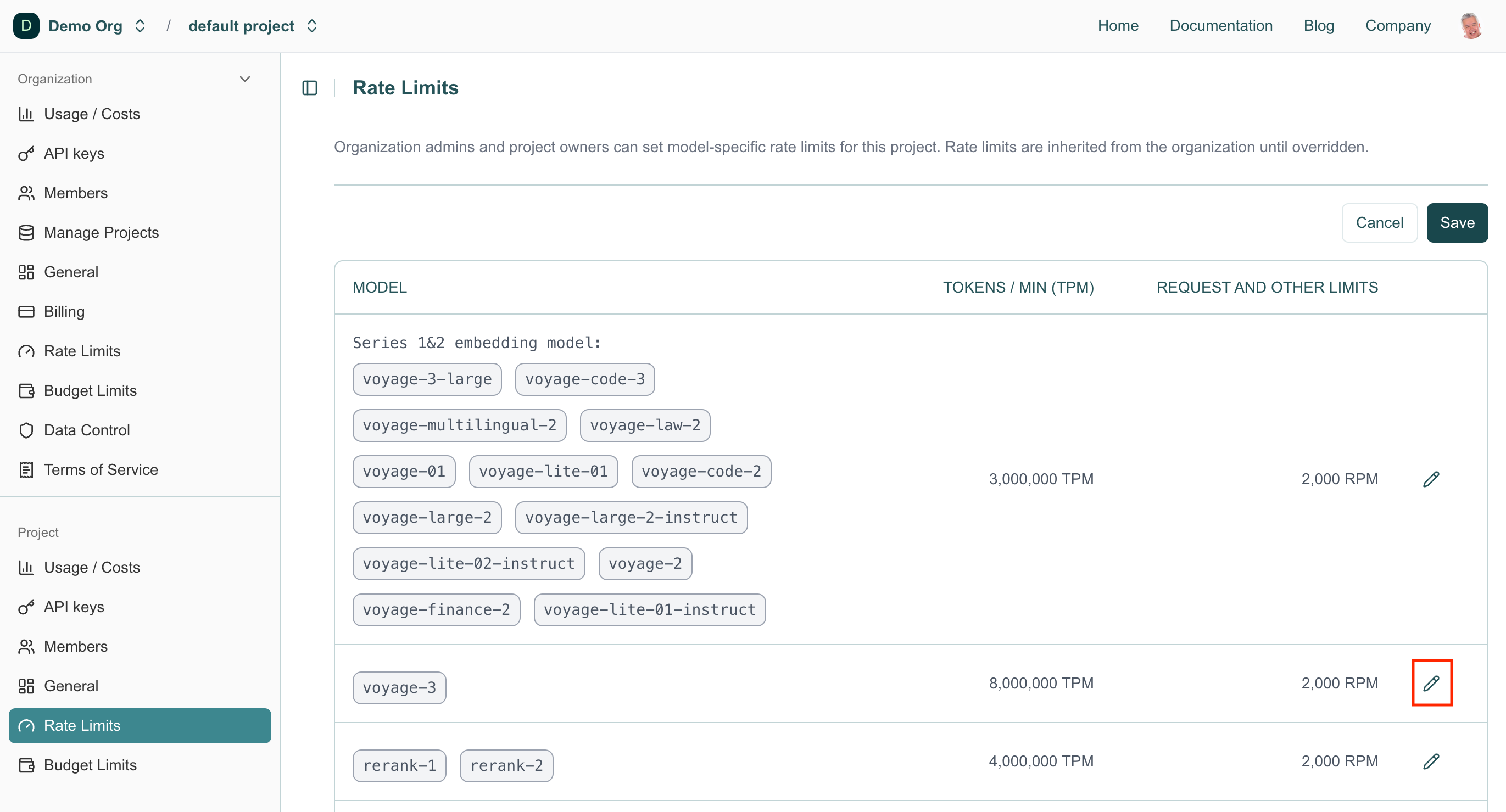
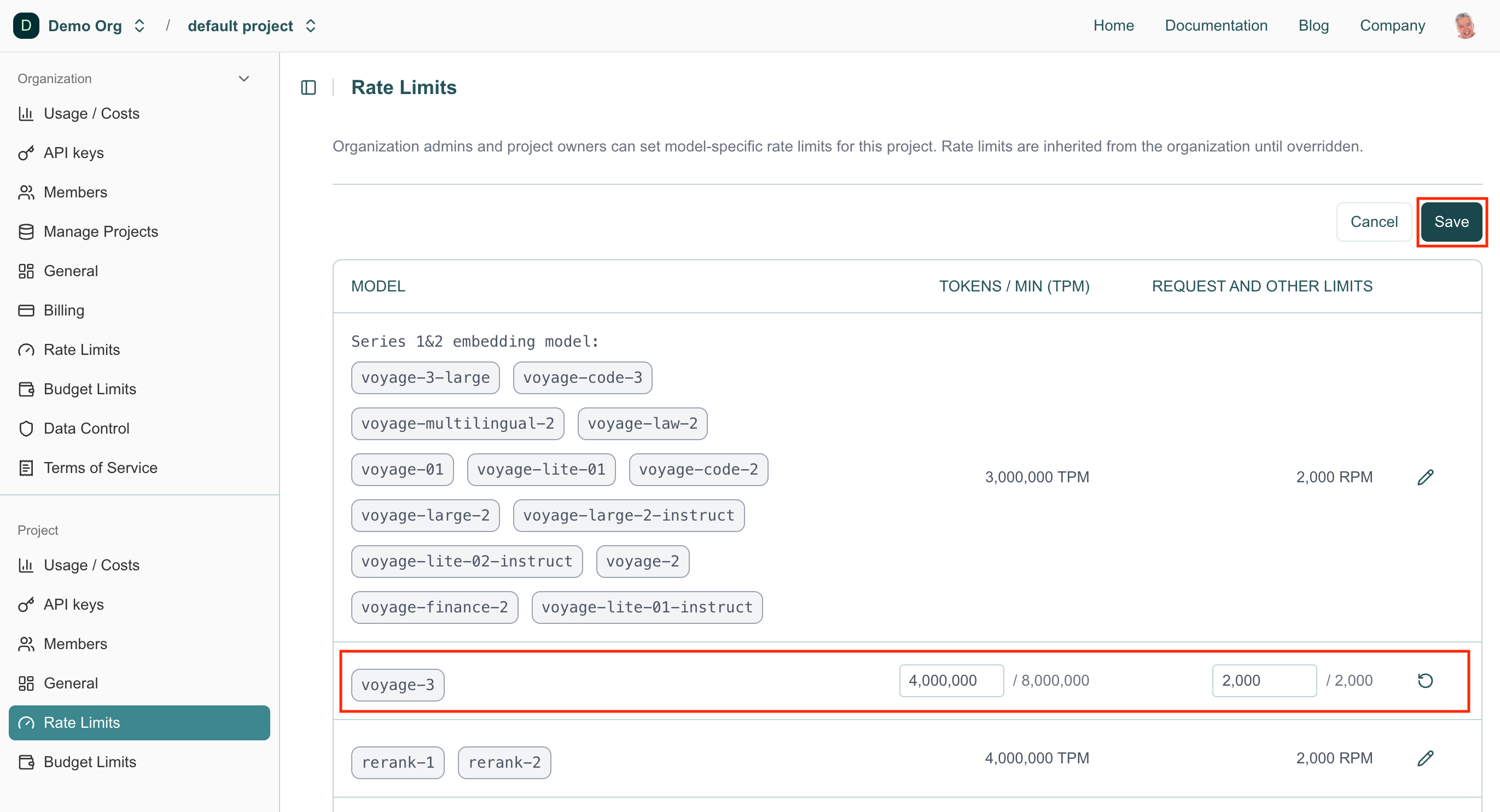
Enter the desired rate limits in the corresponding fields and click Save in the upper-right corner to apply your changes.
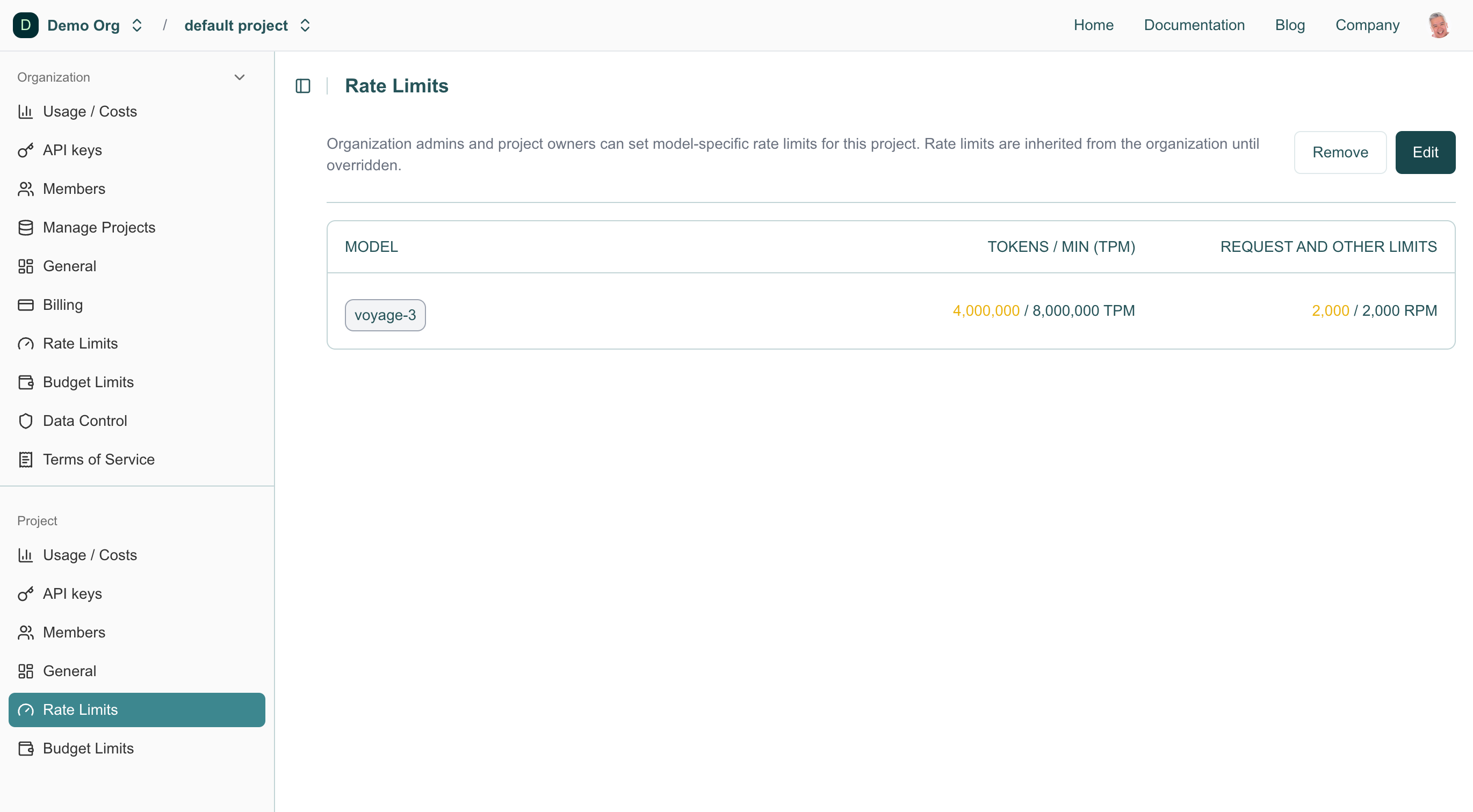
Any project rate limits not directly inherited from the organization are summarized on the project’s Rate Limits section.
Why do we have rate limits?
Rate limits are commonly adopted in APIs, serving several vital purposes:
- Rate limits promote equitable access to the API for all users. If one individual or organization generates an excessive volume of requests, it could potentially impede the API's performance for others. Through rate limiting, Voyage ensures that a larger number of users can utilize the API without encountering performance issues.
- Rate limits enable Voyage AI to effectively manage the workload on its infrastructure. Sudden and substantial spikes in API requests could strain server resources and lead to performance degradation. By establishing rate limits, Voyage can effectively maintain a consistent and reliable experience for all users.
- They act as a safeguard against potential abuse or misuse of the API. For instance, malicious actors might attempt to inundate the API with excessive requests to overload it or disrupt its services. By instituting rate limits, Voyage can thwart such nefarious activities.
What happens if I exceed the rate limit?
If you exceed the rate limit, you will receive an error message with the code 429. For ways to avoid hitting rate limits, see the section below.
Your rate limits automatically increase as your Voyage API usage and spending grow, progressing you into higher usage tiers. Tier 1 requires you add a payment method in the billing page for the appropriate organization in Voyage dashboard. Even with a payment method entered, the free tokens (e.g., 200M tokens for Voyage series 3) will still apply. See our pricing for the free tokens for your model.
You can also purchase usage credits to accelerate tier progression and increase your rate limits faster. For example, purchasing $100 of usage credits automatically upgrades you to Tier 2, doubling the rate limits of usage Tier 1. See the FAQ for details and instructions.
How can I avoid hitting rate limits?
In this section, we’ll offer some tips to avoid and manage rate limit errors. We will provide code snippets to demonstrate these tips and as a starting point for you to use. The code snippets assume you've properly installed the Voyage AI python package and have a configured API key. You can use the following boilerplate code with all of the provided code snippets.
import voyageai
vo = voyageai.Client()
documents = [
"The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.",
"Photosynthesis in plants converts light energy into glucose and produces essential oxygen.",
"20th-century innovations, from radios to smartphones, centered on electronic advancements.",
"Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.",
"Apple’s conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.",
"Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature."
]Use larger batches
If you have many documents to embed, you can increase the number of documents you embed per request and increase your overall throughput by sending larger batches. A "batch" is the collection of documents you are embedding in one request, and the "batch size" is the number of documents in the batch, meaning the length of the list of documents.
For example, assume you want to vectorize 512 documents. If you used a batch size of 1, then this would require 512 requests and you could hit your RPM limit. However, if you used a batch size of 128, then this would require only 4 requests and you would not hit your RPM limit. You can control the batch size by changing the number of documents you provide in the request, and using larger batch sizes will reduce your overall RPM for a given number of documents.
The following are a compact code to vectorize documents in batches of size 128, and a more verbose code printing out useful runtime logs.
# Embed more than 128 documents in a for loop.
batch_size = 128
embeddings = []
for i in range(0, len(documents), batch_size):
embeddings += vo.embed(
documents[i:i + batch_size], model="voyage-3.5", input_type="document"
).embeddings# Embed more than 128 documents in a for loop.
# Note: it requires the tokenizers package, which can be installed with `pip install tokenizers`
batch_size = 128
print("Total documents:", len(documents))
embeddings = []
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
print(f"Embedding documents {i} to {i + len(batch) - 1}")
print("Total tokens:", vo.count_tokens(batch))
batch_embeddings = vo.embed(
batch, model="voyage-3.5", input_type="document"
).embeddings
embeddings += batch_embeddings
print("Embeddings preview:", embeddings[0][:5])Finally, you will need to consider the API maximum batch size and tokens when selecting your batch size. You cannot exceed the API max batch size, and if you have longer documents, the token limit per request may constrain you to a smaller batch size.
Set a wait period
Another way to manage rate limit errors is to simply make requests less frequently. This applies to both RPM and TPM. You can do this by pacing your requests, and the most straightforward approach is inserting a wait period between each request.
import time
batch_size = 128
embeddings = []
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
embeddings += vo.embed(
batch, model="voyage-3.5", input_type="document"
).embeddings
# Add a small amount of sleep in between each iteration
time.sleep(0.1)Exponential Backoff
One strategy is to backoff once you’ve hit your rate limit (i.e., receive a 429 error). With this strategy, you wait for an exponentially increased time after receiving a rate limit error before trying again. This continues until the request is successful or until a maximum number of retries is reached. For example, if your initial wait time was 1 second and you got three consecutive rate limit errors before success, you would wait 1, 2, and 4 seconds after each rate limit error, respectively, before re-sending the request.
The following code snippet demonstrates how to implement exponential backoff (with a little bit of jitter) in Python using the tenacity package.
# Note: it requires the tenacity package, which can be installed with `pip install tenacity`
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
)
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(6))
def embed_with_backoff(**kwargs):
return vo.embed(**kwargs)
embed_with_backoff(texts=documents, model="voyage-3.5", input_type="document")Request rate limit increase
If the above methods are insufficient for your use case, please let us know and request a rate limit increase.
How do organization limits affect my project limits?
Rate limits can be set at the project level by the organization Admin. Project-level rate limits must not exceed the organization’s corresponding rate limit. However, if the organization rate limit is reached first, projects may be rate-limited to a lower rate. This can occur when the sum of all project rate limits exceeds the organization limit.
Consider an organization rate limit O with three projects with rate limits P1, P2, and P3. The table below illustrates three scenarios where the sum of the project rate limits is less than, equal to, or greater than the organization rate limit. For each scenario, the table indicates whether the organization limit can be reached and whether one project’s usage can impact another.
| Scenario 1 P1 + P2 + P3 < O | Scenario 2 P1 + P2 + P3 = O | Scenario 3 P1 + P2 + P3 > O | |
|---|---|---|---|
| Scenario Description | Sum of all project rate limits less than organization limit | Sum of all project rate limits equal toorganization limit | Sum of all project rate limits greater than organization limit |
| Can the organization limit be reached? | No, even if all projects reach their rate limits, the organization rate limit will not be exceeded. | Yes, if all projects reach their rate limits, the organization limit will also be reached. | Yes, since the sum of all project rate limits exceeds the organization limit, the organization limit can be reached before individual projects hit their own limits |
| Can one project’s usage impact another? | No. | No. | Yes. If projects collectively consume enough usage to reach the organization limit before any or all projects reach their individual limits, projects can be rate-limited to a lower rate than their individual limits. |
Updated 7 months ago