

FAQ
General
Why do Voyage embeddings have superior quality?
Embedding models, much like generative models, rely on powerful neural networks (often transformer-based) to capture and compress semantic context. And, much like generative models, they’re incredibly hard to train. Voyage is a team of leading AI researchers who each have experience in training embedding models for 5+ years. We refine every component, from model architecture and data collection to selecting suitable loss functions and optimizers. Please see our blog for more details.
Model
What text embedding models are available, and which one should I use?
For general-purpose embedding, our recommendation is voyage-4-large for the best quality, voyage-4-lite for the lowest latency and cost, and voyage-4 for a balance between the two. Notably, all 4 series models are compatible with each other . voyage-4 also outperforms all major competitors in retrieval quality while being offered at a lower price point. For retrieval, please use the input_type parameter to specify whether the text is a query or document, which adds instructions on the backend.
If your application is in a domain addressed by one of our domain-specific embedding models, we recommend using that model. Specifically:
voyage-law-2is recommended for retrieval tasks in the legal domain.voyage-code-3is recommended for code-related tasks and programming documentation.voyage-finance-2is recommended for finance-related tasks.
Which similarity function should I use?
You can use Voyage embeddings with either dot-product similarity, cosine similarity, or Euclidean distance. An explanation about embedding similarity can be found here.
Voyage AI embeddings are normalized to length 1, which means that:
- Cosine similarity is equivalent to dot-product similarity, while the latter can be computed more quickly.
- Cosine similarity and Euclidean distance will result in the identical rankings.
What is the relationship between characters, words, and tokens?
Please see this section.
When and how should I use the input_type parameter?
input_type parameter?For retrieval/search tasks and use cases (e.g., RAG), where a "query" is used to search for relevant information among a collection of data referred to as "documents," we recommend specifying whether your inputs are intended as queries or documents by setting input_type to query or document, respectively. Do not omit input_type or set input_type=None. Specifying whether inputs are queries or documents helps the model create more effective vectors tailored for retrieval/search tasks.
When using the input_type parameter, special prompts are prepended to the input text prior to embedding. Specifically:
Prompts associated withinput_type
- For a query, the prompt is “Represent the query for retrieving supporting documents: “.
- For a document, the prompt is “Represent the document for retrieval: “.
Example:
- When
input_type="query", a query like "When is Apple's conference call scheduled?" will become "Represent the query for retrieving supporting documents: When is Apple's conference call scheduled?"- When
input_type="document", a query like "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET." will become "Represent the document for retrieval: Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET."
voyage-large-2-instruct, as the name suggests, is trained to be responsive to additional instructions that are prepended to the input text. For classification, clustering, or other MTEB subtasks, please use the instructions here.
What is the total number of tokens for the rerankers?
We define the total number of tokens as the “(number of query tokens × the number of documents) + sum of the number of tokens in all documents". This cannot exceed 600K for rerank-2.5, rerank-2.5-lite, rerank-2, and rerank-2-lite; and 300K for rerank-1 and rerank-lite-1. However, if your application is latency-sensitive, we recommend you to use rerank-2.5-lite and use no more than 200K total tokens per request.
Usage
How do I get the Voyage API key?
Upon creating an account, we instantly generate an API key for you. Once signed in, access your API key by clicking the "Create new API key" button in the dashboard.
What are the rate limits for the Voyage API?
Please see the rate limit guide.
How can I retrieve nearest text quickly if I have a large corpus?
To efficiently retrieve the nearest texts from a sizable corpus, you can use a vector database. We recommend using:
- MongoDB, a versatile database with best-in-class vector search capabilities
MongoDB and the document data model are the best for representing all the variety of data in the world—whether it's structured, semi-structured, or unstructured (vector) data.
Here are some other choices:
- Turbopuffer, a fast serverless search engine that combines vector and full-text search
- Pinecone, a fully managed vector database
- Zilliz, a vector database for enterprise
- Chroma, an open-source embeddings store
- Elasticsearch, a popular search/analytics engine and vector database
- Milvus, a vector database built for scalable similarity search
- Qdrant, a vector search engine
- Weaviate, an open source, AI-native vector database
What is Base64 encoding?
Base64 encoding converts binary data, such as images, into a sequence of printable characters. It is commonly used to encode data that needs to be stored or transferred over media designed to handle textual data, such as HTTPS requests. The encoding ensures that the data remains intact without modification during transmission.
Python comes with a native base64 library. Here’s an example using the Python base64 library to create a Base64 image:
import base64
# Replace 'banana.jpg' with the path to your image file
image_path = 'banana.jpg'
# Open the image file in binary mode
with open(image_path, "rb") as image_file:
# Read the binary data
image_data = image_file.read()
# Encode the binary data to Base64
base64_encoded_data = base64.b64encode(image_data)
# Convert the base64 bytes to a string
base64_string = base64_encoded_data.decode("utf-8")Here’s how you can create a Base64 image with a function and vectorize it with voyage-multimodal-3.5:
import base64
import mimetypes
import voyageai
vo = voyageai.Client()
# This will automatically use the environment variable VOYAGE_API_KEY.
# Alternatively, you can use vo = voyageai.Client(api_key="<your secret key>")
# Convert image to Base64 image
def b64encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Image path
image_path = 'banana.jpg'
# Get media type
mediatype, _ = mimetypes.guess_type(image_path)
# Input with text and a Base64 encoded image
inputs = [
{
"content": [
{ "type": "text", "text": "This is a banana." },
{ "type": "image_base64", "image_base64": f"data:{mediatype};base64,{b64encode_image(image_path)}" }
]
}
]
# Vectorize inputs
result = vo.multimodal_embed(inputs, model="voyage-multimodal-3.5", input_type="document")
print(result.embeddings)[
[0.0181884765625, -0.01019287109375, 0.021240234375,...]
]What is Pillow?
Pillow is a widely used Python library for image processing, providing powerful tools to open, manipulate, and save various image file formats. It is popular because it is simple to use, well-documented, and covers many use cases. The following example demonstrates some common tasks with Pillow, such as opening, showing, resizing, and saving images. It also demonstrates retrieving metadata like width, height, and pixel count. Check out the Pillow docs for more details.
from PIL import Image
# Open an image
img = Image.open('banana.jpg')
# Show image
img.show()
# Get image width, height, and pixels
width, height = img.size # Get image width and height
num_pixels = width * height # Calculate number of pixels
print(f"Width: {width} pixels")
print(f"Height: {height} pixels")
print(f"Total Pixels: {num_pixels}")
# Resize image to 200 pixels by 150 pixels
new_size = (200, 150) # Example size: 200x150 pixels
# Resize the image
resized_img = img.resize(new_size)
# Show resized image
resized_img.show()
# Save resized image
resized_img.save('banana-200px-by-150px.jpg')Billing and Budgets
When will I receive the bill?
The first 200 million tokens are free for every account, and subsequent usage is priced on a per-token basis. See our Pricing page for details
You can add payment methods to your account in the dashboard. We will bill monthly. You can expect a credit card charge around the 2nd of each month for the usage of the past month.
How can I set up prepaid billing?
Prepaid billing allows API users to pre-purchase usage credits, which are applied to their monthly invoice. API usage is first deducted from prepaid credits, and any usage exceeding the purchased credits is billed separately. Prepaid billing helps developers plan upfront, providing greater predictability for budgeting and spend management.
Setting up prepaid billing. To prepay and add a credit balance, you must have a payment method on file. Navigate to the Billing section under Organization in the navigation sidebar. In the Overview tab, click Add to credit balance to open the Configure Payment modal.
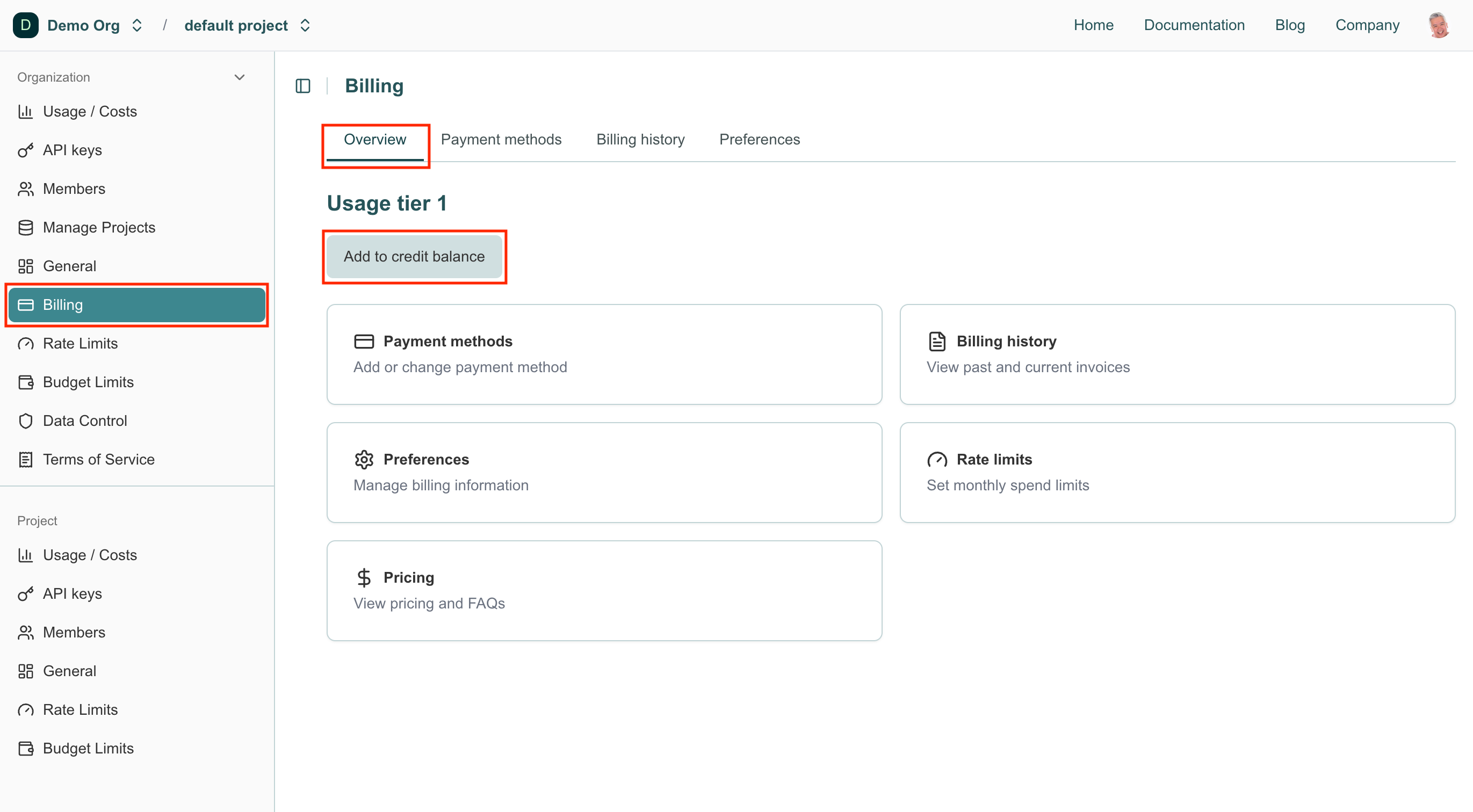
Enter the amount you want to prepay in the Initial credit purchase field. Optionally, you can enable automatic recharge and specify an amount to restore your credit balance when it falls below a set threshold.
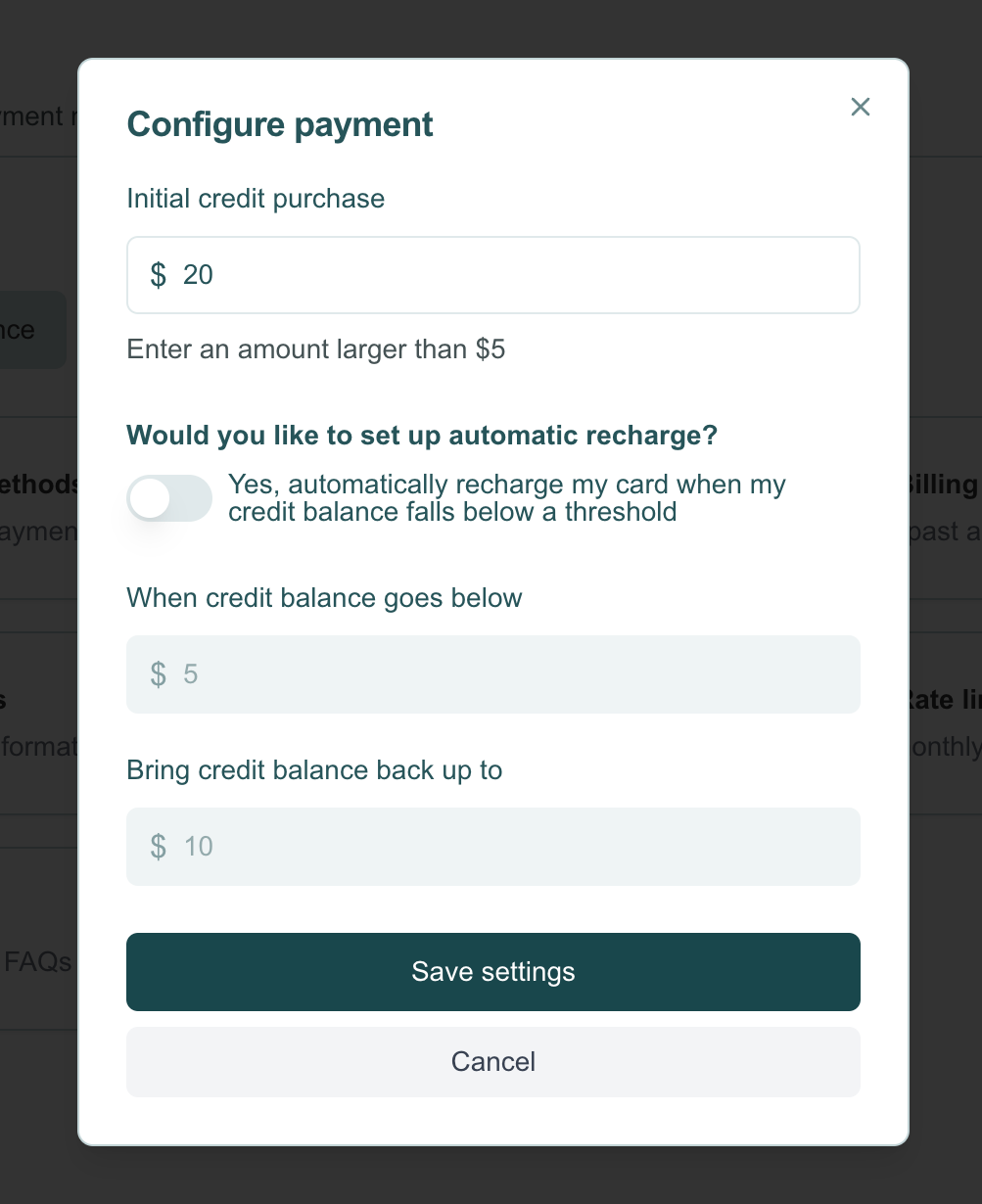
Service Credit Terms and Expiration. Please note that any purchased credits will expire after 1 year, and they are non-refundable.
Others
What are your policies in regard to protecting customer data?
For Voyage-hosted model API endpoints, customers can opt-out from Voyage storing and using their data for future model training so that there is a zero-day retention of the data.
To opt out, you must have a payment method on file and be an organization Admin. Log into your account dashboard and navigate to the Terms of Service section under Organization in the navigation sidebar. Scroll to the bottom and toggle the Opted In slider to Opted Out.

You won’t be able to opt-in again in the dashboard after you opt out. If you are interested in opting-in again after opting-out, please contact [email protected].
Is fine-tuning available?
Currently we offer fine-tuned embeddings through subscription. Please email Tengyu Ma (CEO) at [email protected] if you are interested.
How to contact us?
Please email us at [email protected] for inquiries and customer support.
How to get updates from Voyage?
Follow us on twitter and/or linkedin for more updates!
To subscribe to our newsletter, feel free to send us an email at [email protected].
Updated 7 months ago