

Quickstart Tutorial
This tutorial is a step-by-step guidance on implementing a specialized chatbot with RAG stack using embedding models (e.g., Voyage embeddings) and large language models (LLMs). We start with a brief overview of the retrieval augmented generation (RAG) stack. Then, we’ll briefly go through the preparation and vectorization of data (i.e. embeddings). We’ll show how to do retrieval with embeddings as well as some additional refinements with rerankers. Finally, we’ll put this all together to create a simple RAG chatbot.
Brief overview of the RAG stack
A typical RAG stack is illustrated in Figure 1. When presented with a search query, our initial step involves employing the embedding model, such as Voyage embeddings, to derive the vector representation of the query. Subsequently, we conduct a document search, identifying the most relevant documents from a vector store. The most relevant document is then selected and combined with the original query. This composite input is then submitted to a generative model to generate a comprehensive response to the query. This RAG stack can be further refined with reranking, which we'll discuss in a later section.
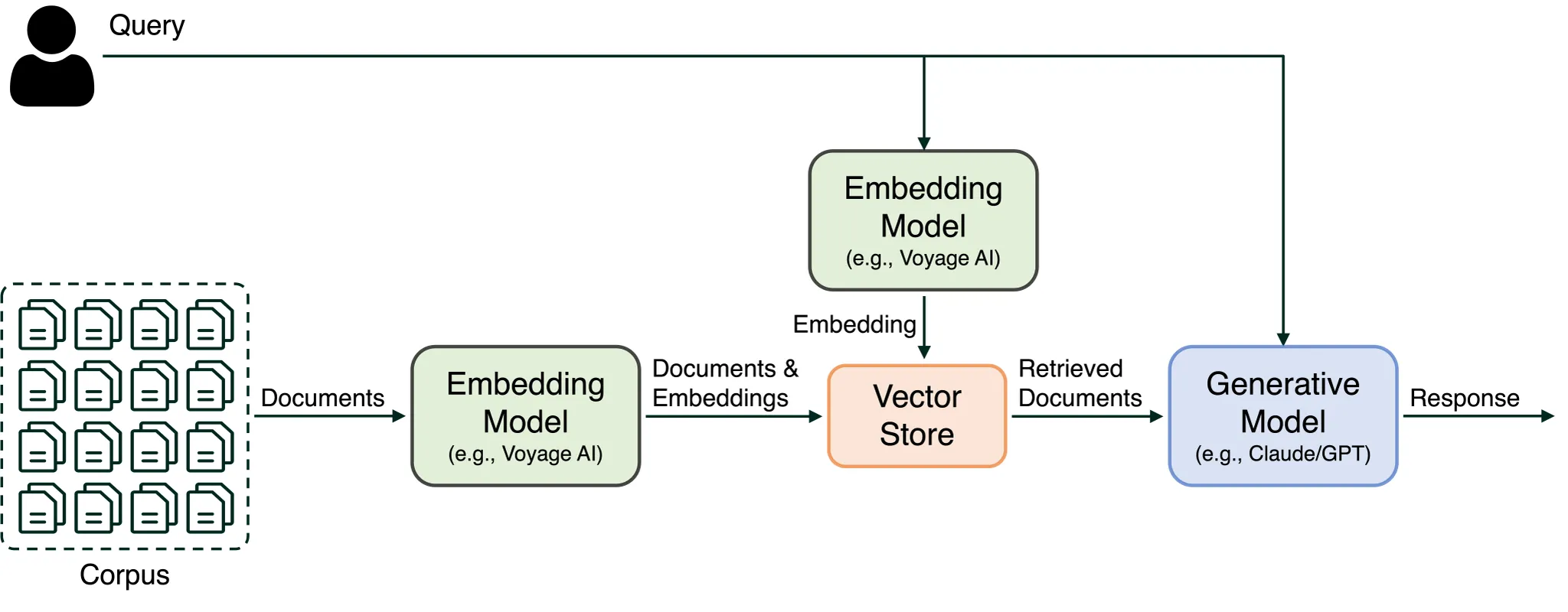
Figure 1: Typical RAG stack
Prepare data
You will need a corpus of documents that your chatbot will specialize in. You can choose to save your documents as demonstrated below or use the following set of documents as a starting point.
documents = [
"The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.",
"Photosynthesis in plants converts light energy into glucose and produces essential oxygen.",
"20th-century innovations, from radios to smartphones, centered on electronic advancements.",
"Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.",
"Apple’s conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.",
"Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature."
]We have additional examples available in this link for you to download and test.
Vectorize/embed the documents
First, follow the installation guide to install the Voyage Python package and get your API key. Then, we can use the Python client to create embeddings.
import voyageai
vo = voyageai.Client()
# This will automatically use the environment variable VOYAGE_API_KEY.
# Alternatively, you can use vo = voyageai.Client(api_key="<your secret key>")
# Embed the documents
documents_embeddings = vo.embed(
documents, model="voyage-4-large", input_type="document"
).embeddingsimport voyageai
vo = voyageai.Client()
# This will automatically use the environment variable VOYAGE_API_KEY.
# Alternatively, you can use vo = voyageai.Client(api_key="<your secret key>")
# Embed more than 128 documents with a for loop
batch_size = 128
documents_embeddings = [
vo.embed(
documents[i : i + batch_size],
model="voyage-4-large",
input_type="document",
).embeddings
for i in range(0, len(documents), batch_size)
]Notes on Tokenization
Tokenization
Voyage has a limit on the context length and the number of total tokens in each request (see here for details). To comply with this limit, you can preview the tokenized results by our tokenizer and count the total tokens in the input.
# Print the tokenized results
tokenized = vo.tokenize(documents)
for i in range(len(documents)):
print(tokenized[i].tokens)
# Count the total tokens
print(vo.count_tokens(documents))A minimalist retrieval system
The main feature of the embeddings is that the cosine similarity between two embeddings captures the semantic relatedness of the corresponding original passages. This allows us to use the embeddings to do semantic retrieval / search.
Suppose the user sends a "query" (e.g., a question or a comment) to the chatbot:
query = "When is Apple's conference call scheduled?"To find out the document that is most similar to the query among the existing data, we can first embed/vectorize the query:
# Get the embedding of the query
query_embedding = vo.embed([query], model="voyage-4-large", input_type="query").embeddings[0]Nearest neighbor Search: We can find the closest embedding among the documents based on the cosine similarity, and retrieve the corresponding document.
# Compute the similarity
# Voyage embeddings are normalized to length 1, therefore dot-product and cosine
# similarity are the same.
similarities = np.dot(doc_embds, query_embd)
retrieved_id = np.argmax(similarities)
print(documents[retrieved_id])k-nearest neighbors Search (k-NN): It is often useful to retrieve not only the closest document but also the k most closest documents. We can use any k_nearest_neighbors search algorithm to achieve this goal.
# Use the k-nearest neighbor algorithm to identify the top-k documents with the highest similarity
retrieved_embds, retrieved_embd_indices = k_nearest_neighbors(
query_embedding, documents_embeddings, k=3
)
retrieved_docs = [documents[index] for index in retrieved_embd_indices]Notes on Cosine Similarity, Nearest Neighbor Search, and Vector Database
Cosine Similarity
Given vectors q and d, the cosine similarity is defined as:
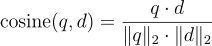
where q⋅d is the dot product of the vectors q and d, and ||q||, ||d|| are the magnitude (or length) of vectors q and d, respectively. The term "cosine similarity" derives its name from the fact that it measures the cosine of the angle between two vectors. A bigger cosine similarity means the two vectors are closer.
Nearest Neighbor Search
Given a vector q (the embedding for the query) and a sequence of embeddings d_1, ..., d_n for the n documents in the pool, we can define the nearest neighbor of vector q in the pool through the computation of cosine similarity:
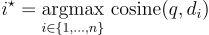
k-nearest neighbors Search (k-NN): Sort the documents based on their cosine similarities to the query in descending order (higher similarity comes first), obtaining an ordered list of documents. Select the k documents with the highest cosine similarities, which represent the k nearest neighbors of the query.
The k_nearest_neighbors function is implemented below:
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def k_nearest_neighbors(query_embedding, documents_embeddings, k=5):
# Convert to numpy array
query_embedding = np.array(query_embedding)
documents_embeddings = np.array(documents_embeddings)
# Reshape the query vector embedding to a matrix of shape (1, n) to make it
# compatible with cosine_similarity
query_embedding = query_embedding.reshape(1, -1)
# Calculate the similarity for each item in data
cosine_sim = cosine_similarity(query_embedding, documents_embeddings)
# Sort the data by similarity in descending order and take the top k items
sorted_indices = np.argsort(cosine_sim[0])[::-1]
# Take the top k related embeddings
top_k_related_indices = sorted_indices[:k]
top_k_related_embeddings = documents_embeddings[sorted_indices[:k]]
top_k_related_embeddings = [
list(row[:]) for row in top_k_related_embeddings
] # convert to list
return top_k_related_embeddings, top_k_related_indicesWhen the number of document is huge, one will need to use a vector database (e.g. MongoDB Atlas) to compute (approximate) k-nearest neighbor efficiently, which is beyond the scope of this tutorial.
Vector Database
Vector Database is a specialized database or data platform designed to cater to the unique needs of applications and industries that rely heavily on vector-based data. This database is engineered to efficiently store, manage, and retrieve vector data, which can include a wide range of information such as spatial data, molecular sequences, time-series data, and more. VectorDB offers a robust set of tools and features tailored to support the indexing, querying, and analysis of vector data, making it a valuable resource for researchers, data scientists, and businesses working with complex datasets that exhibit vector-like characteristics.
Refinement with rerankers
We can further refine our embedding-based retrieval with rerankers. The refined RAG stack with a reranker is illustrated in Figure 2. Here, the retrieved documents from the vector store are subsequently passed to a reranker, which then reranks the documents for semantic relevance against the query and produces a more relevant and smaller set of documents for inputting to the generative model.
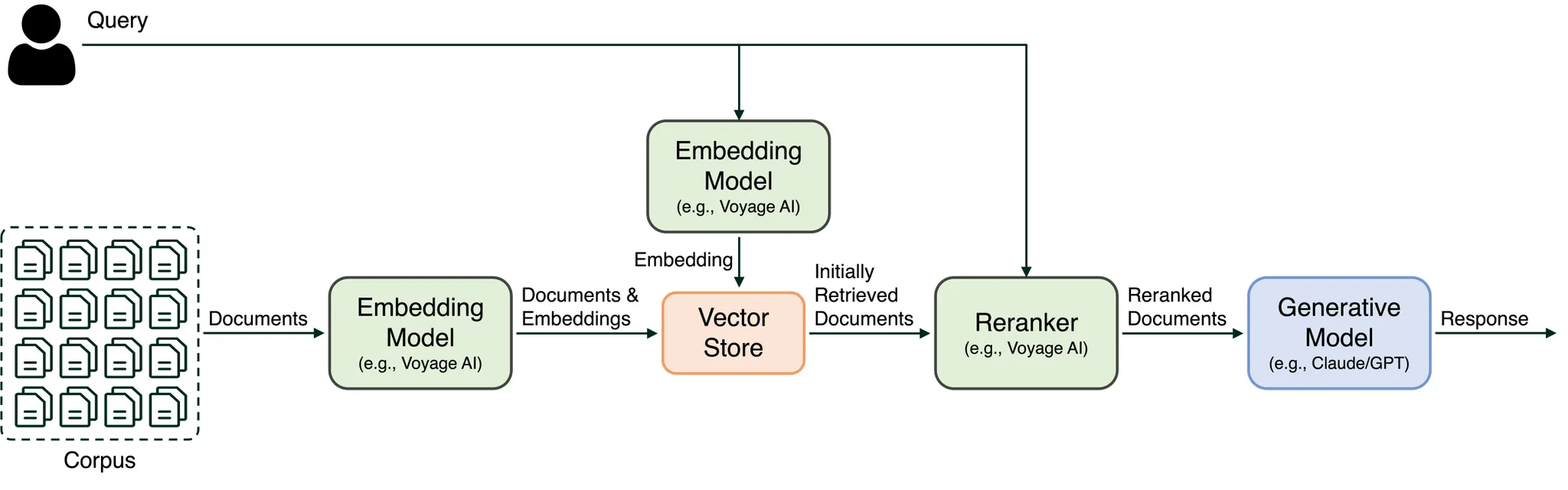
Figure 2: RAG stack with reranker
Below, we send initially retrieved documents to the reranker to obtain the top-3 most relevant documents.
# Reranking
documents_reranked = vo.rerank(query, documents, model="rerank-2.5", top_k=3)We see that the reranker properly ranks the Apple conference call document as the most relevant to the query.
for r in documents_reranked.results:
print(f"Document: {r.document}")
print(f"Relevance Score: {r.relevance_score}")
print(f"Index: {r.index}")
print()Output:
Document: Apple’s conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.
Relevance Score: 0.94140625
Index: 0
Document: 20th-century innovations, from radios to smartphones, centered on electronic advancements.
Relevance Score: 0.28515625
Index: 1
Document: Photosynthesis in plants converts light energy into glucose and produces essential oxygen.
Relevance Score: 0.255859375
Index: 2A minimalist RAG chatbot
The Retrieval-Augmented Generation (RAG) chatbot represents a cutting-edge approach in conversational artificial intelligence. RAG combines the powers of retrieval-based and generative methods to produce more accurate and contextually relevant responses. RAG can leverage a large corpora of text to retrieve relevant documents and then send those documents to language models, such as Claude or GPT, to generate replies. This methodology ensures that the chatbot's answers are both informed by vast amounts of information and tailored to the specifics of the user's query.
Suppose you have implemented a semantic search system as described in the previous section—either with or without a reranker. As a result of the search process, you have retrieved the most relevant document, referred to as retrieved_doc. We can craft a prompt with this context which we can use as input to the language model.
# Take the retrieved document and use it as a prompt for the text generation model
prompt = f"Based on the information: '{retrieved_doc}', generate a response of {query}"Now you can utilize a text generation model like Claude 4.5 Sonnet to craft a response based on the provided query and the retrieved document.
Install the anthropic package first:
pip install anthropicThen run the following code:
import anthropic
# Initialize Anthropic API
client = anthropic.Anthropic(api_key="YOUR ANTHROPIC API KEY")
message = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
print(message.content[0].text)Output:
Apple's conference call is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.Output without using Voyage retrieved documents
I don't have information about a specific upcoming Apple conference call. Apple typically holds quarterly earnings conference calls, but without a more precise timeframe or context, I can't provide the exact date of their next scheduled call. For the most up-to-date information on Apple's upcoming conference calls or earnings releases, you should check Apple's investor relations website or contact their investor relations department directly.You can do the same with GPT-4o as well. Install the openai package first:
pip install openaiThen run the following code:
from openai import OpenAI
# Initialize OpenAI client
client = OpenAI(api_key="YOUR OPENAI API KEY")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
],
)
print(response.choices[0].message.content)Output:
Apple's conference call is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.Output without using Voyage retrieved documents:
Apple's conference calls are typically scheduled to discuss quarterly earnings. They usually announce these dates a few weeks in advance. For the specific date and time of the next Apple conference call, I recommend checking Apple's Investor Relations website or recent press releases, as they will have the most accurate and up-to-date information. If you're looking for the scheduled call for a specific quarter, these events usually occur a few weeks after the end of a fiscal quarter, with Apple's fiscal year ending on the last Saturday of September.Colab examples
To execute the code examples provided above in Google Colab, please review and run the code snippets in Google Colaboratory.
Updated 7 months ago