

MongoDB Voyage AI Models in AWS
Deploy MongoDB Voyage AI models using AWS Marketplace
AWS Marketplace model packages are containerized solutions that include the model and inference code. You deploy them in your account and virtual private cloud (VPC). Model packages have the following key benefits:
- Data flow and access control: Deploy models in your account and VPC to maintain full control over data flow and API access. This addresses data privacy risks associated with third-party or multi-tenant serving.
- Reliability and compliance backed by AWS: AWS serves as your sub-processor, so you inherit all AWS reliability and compliance guarantees.
- Billing and payment through AWS: Use your existing AWS billing information and credits to purchase MongoDB Voyage AI models through marketplace listings. You don't need to manage a separate third-party payment and billing system.
You can deploy a model package as a real-time inference API endpoint or a batch transform job. Real-time inference API endpoints provide persistent, fully managed API endpoints for request-by-request inference. Batch transform jobs run finite execution processes for bulk inference on datasets, writing predictions to a file. Both deployment types run on AWS instances, such as GPUs.
Available Models
To see which models are available on AWS Marketplace, go to the MongoDB Marketplace Seller Profile.
Pricing
Pricing for the use of a MongoDB Voyage AI model package consists of software pricing and infrastructure pricing, both at an hourly rate. Software pricing covers the cost of model usage, while your total hourly cost is the sum of the software pricing and the infrastructure pricing. Pricing rates vary based on deployment type (real-time inference API endpoint versus batch transform job), instance type, and region. All MongoDB Voyage models come with a free trial. You can find the pricing details for each model package on the product listing page in the AWS Marketplace.
The following sections demonstrate how to subscribe and deploy the models.
Prerequisites
You must have the following AWS identity access management (IAM) permissions to subscribe to AWS Marketplace listings.
- AmazonSageMakerFullAccess (AWS Managed Policy)
- aws-marketplace:ViewSubscriptions
- aws-marketplace:Subscribe
- aws-marketplace:Unsubscribe
To add them, sign into your AWS account console and review the AWS documentation for instructions.
Procedure
To subscribe by using the AWS Marketplace:
-
Select the MongoDB Voyage AI model package to subscribe to in the AWS Marketplace.
-
Click Continue to Subscribe.
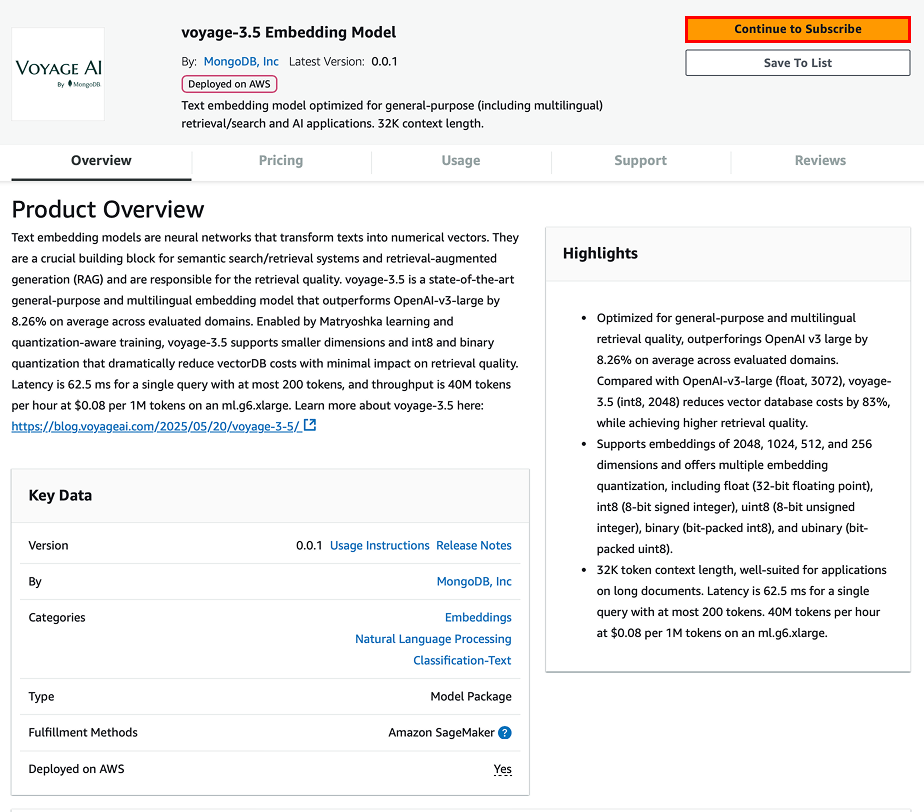
- Click Accept Offer.
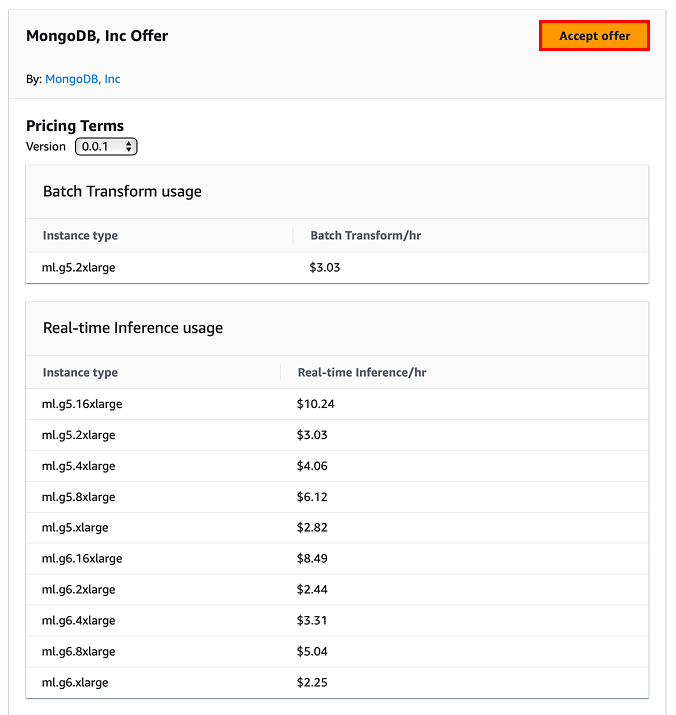
- Confirm you have successfully subscribed and close the window.
You can also confirm and manage your AWS Marketplace subscriptions through the console’s manage subscription page. You can cancel your subscription at any time, but note that canceling your subscription does not terminate your existing real-time inference endpoints or batch transform jobs. To learn more, see Delete Real-Time Inference Endpoints.
Model package deployment requires specific SageMaker instances (e.g., ml.g5.xlarge). The exact quota names for these instances end with “endpoint usage” and “transform job usage” (e.g., “ml.g5.2xlarge for endpoint usage”, and “ml.g5.2xlarge for transform job usage”). These quotas are typically set to zero by default. To request quota increases if needed, go to the SageMaker Service Quotas console.
If you need help subscribing and deploying a MongoDB Voyage AI model package from the AWS Marketplace,
contact MongoDB support.
Model Package Deployment
This section includes guidance on how to deploy a model package using Amazon SageMaker Studio and Jupyter Notebooks.
Amazon SageMaker Studio
Amazon SageMaker Studio is a web-based interface for ML and AI development that includes a hosted notebook environment already authenticated to your AWS account. You can skip this section if you have another preferred Jupyter notebook execution environment, such as your local machine, where you can authenticate to your AWS account from the environment. Follow the SageMaker documentation to launch SageMaker Studio, and then launch a JupyterLab environment.
Jupyter Notebook
You can use the example Jupyter notebook to get started with Python by using the AWS SDK (Boto3) and the Amazon SageMaker Python SDK. You can run the notebook in SageMaker Studio or your preferred Jupyter notebook execution environment after cloning the Voyage AI AWS repo. For example, by running git clone https://github.com/voyage-ai/voyageai-aws.git.
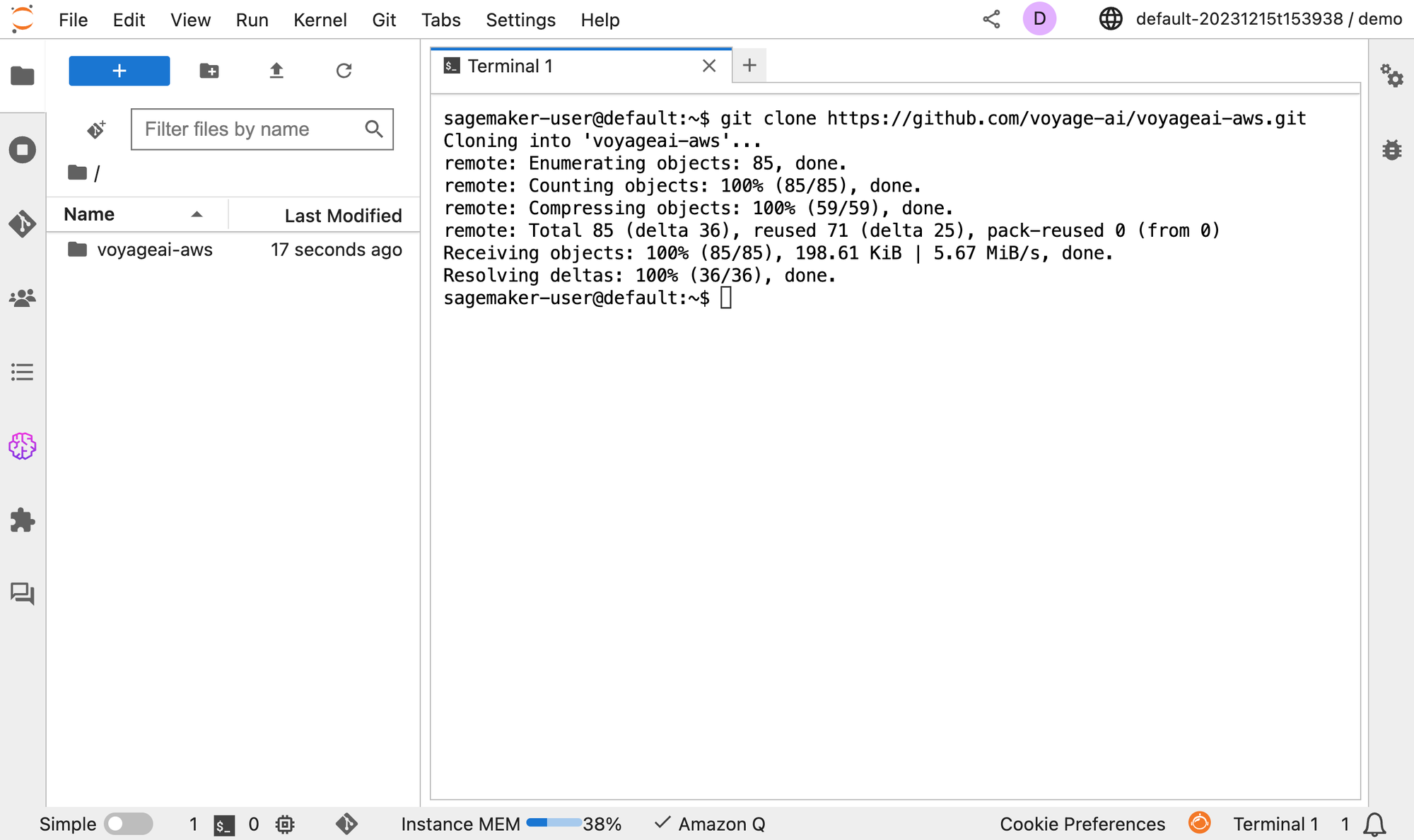
Alternatively, you can directly download the notebook from GitHub and upload it to SageMaker Studio or your preferred notebook environment.
Once the notebook is in SageMaker Studio or your preferred execution environment, you can run the provided code to deploy the models.
Delete Real-Time Inference Endpoints
Do not run real-time inference endpoints longer than necessary. If you do, they might incur wasteful costs and lead to unexpected charges. If you're using the provided Jupyter notebook, ensure that you run the Clean Up code, which deletes the endpoint and associated endpoint configuration. You can manage and delete endpoints through SageMaker Studio or the SageMaker console. To learn more, see AWS documentation.
Advanced Deployment
The Jupyter notebook described in the previous section is meant to get you started and help you learn how to deploy model packages. However, there are several other ways to deploy model packages, such as CloudFormation, the SageMaker Console, and the AWS CLI. These alternative methods might be better suited for your existing production workflows. For example:
- CloudFormation for declarative infrastructure specification
- SageMaker Console for interactive UI-based deployment
- AWS CLI for programmatic shell orchestration
To configure and deploy a model package using these methods:
- Go to the product listing page for the subscribed MongoDB Voyage model from the AWS Marketplace.
- Click on Continue to Subscribe in the upper-right corner.
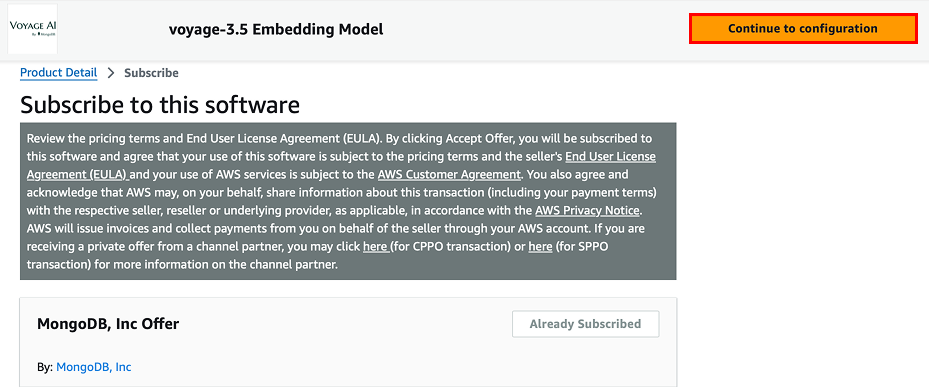
- In the Subscribe to this software page, you should see that you are Already Subscribed. Click on the Continue to configuration button.
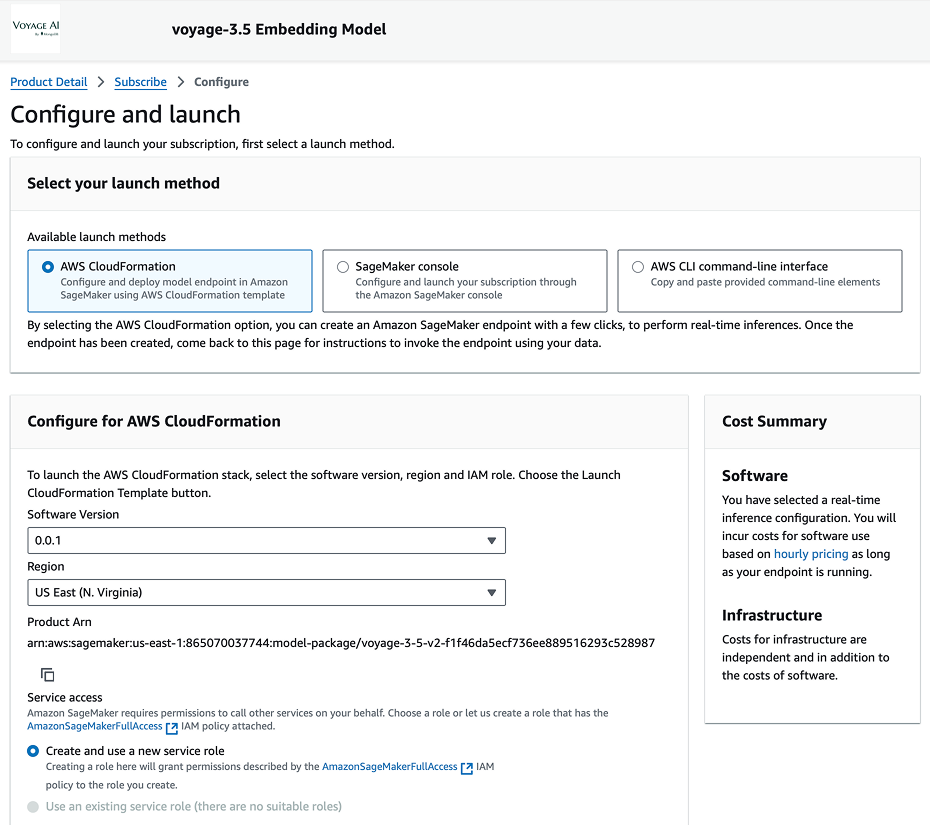
- In the Configure and launch page, you can select your desired launch method. The configuration settings update according to the corresponding instructions and resources for the selected method.
Updated 7 months ago